
Have you encountered the issue of getting null values or blank values when data is read using an SSIS package and exported to a text file?

To illustrate this issue I have a data flow task which reads from an excel file and writes the details to a text file.

We are using an excel connection and a flat-file connection in order to connect the source and the destination using the default settings.



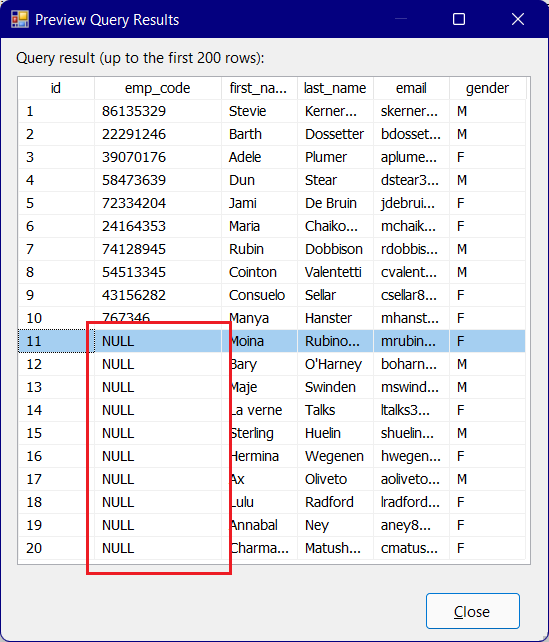
Once the task is executed the null columns be saved as blank values in the destination text files.

Root Cause (As per Microsoft explanation)
The Excel driver reads a certain number of rows (by default, 8 rows) in the specified source to guess at the data type of each column. When a column appears to contain mixed data types, especially numeric data mixed with text data, the driver decides in favour of the majority data type and returns null values for cells that contain data of the other type. (In a tie, the numeric type wins.) Most cell formatting options in the Excel worksheet do not seem to affect this data type determination. You can modify this behaviour of the Excel driver by specifying Import Mode. To specify Import Mode, add IMEX=1 to the value of Extended Properties in the connection string of the Excel connection manager in the Properties window
In order to overcome this issue, we need to do a few things.
Firstly we need to include the parameter "IMEX=1" in the connection string (or in the extended properties.)
Secondly, we need to consider switching the HDR=NO in the connection string (or set FirstRowHasColumnNames to False)
IMEX=1 Option: There are other types which can be used and each denotes a different option. In our case, we need to set it up as 1, which means during import all the data is to be considered as text type.
HDR=NO Option: This option will inform the OLEDB engine not to consider the first row as the header row. This is very important since excel will still determine the data type based on sampling (considering the first 8 rows), and it determines the data type based on the majority number of types.
After doing those changes you will be able to see the data when you preview prior running your package.

But you will face a classic issue in which your data will contain the additional header row containing F1, F2... etc.

I haven't found a way to get rid of these excel column names. Hence I am using a conditional split to remove the header row (1 row in excel which contains the column names [id, emp_code etc...]).
Then I renamed all the columns to give a proper heading instead of showing F1, F2, etc...



Hope this will be helpful to you.




























{kind=link}